Dataset Visualizations
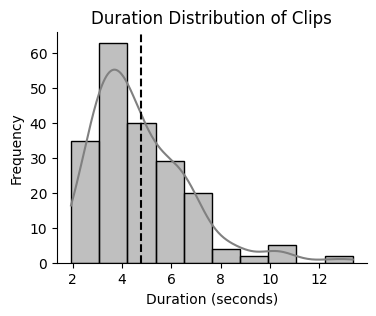
Duration distribution of clips (mean: 4.8 seconds)
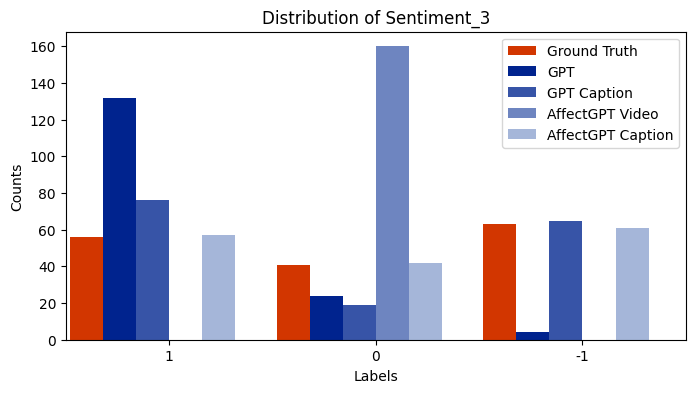
Sentiment distribution across the 7-point scale
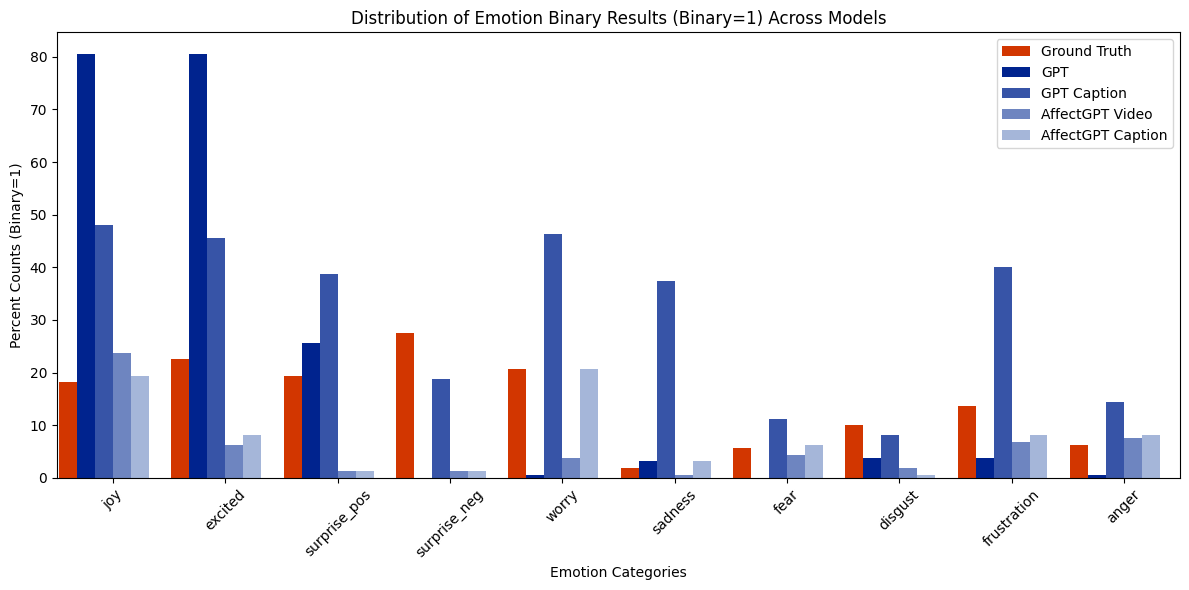
Distribution of emotion categories (binarized presence)
Unlike spoken languages where the use of prosodic features to convey emotion is well studied, indicators of emotion in sign language remain poorly understood, creating communication barriers in critical settings. Sign languages present unique challenges as facial expressions and hand movements simultaneously serve both grammatical and emotional functions. To address this gap, we introduce EmoSign, the first sign video dataset containing sentiment and emotion labels for 200 American Sign Language (ASL) videos. We also collect open-ended descriptions of emotion cues. Annotations were done by 3 Deaf ASL signers with professional interpretation experience. Alongside the annotations, we include baseline models for sentiment and emotion classification. This dataset not only addresses a critical gap in existing sign language research but also establishes a new benchmark for understanding model capabilities in multimodal emotion recognition for sign languages. The dataset is made available at Hugging Face.
EmoSign is the first comprehensive dataset specifically designed for studying emotional expression in American Sign Language (ASL). The dataset addresses a critical gap in sign language research by providing detailed emotion annotations from native ASL signers.
ASL Video Clips
Average duration: 4.8 seconds
Total duration: ~16 minutes
Deaf ASL Annotators
Professional interpreters with native ASL fluency
Emotion Categories
10 specific emotions plus overall sentiment ratings
We built EmoSign using videos from the ASLLRP (American Sign Language Linguistic Research Project) continuous signing corpus. Videos were pre-selected based on emotional expressiveness using VADER sentiment analysis of text captions, then manually curated to ensure a balanced representation of emotions.
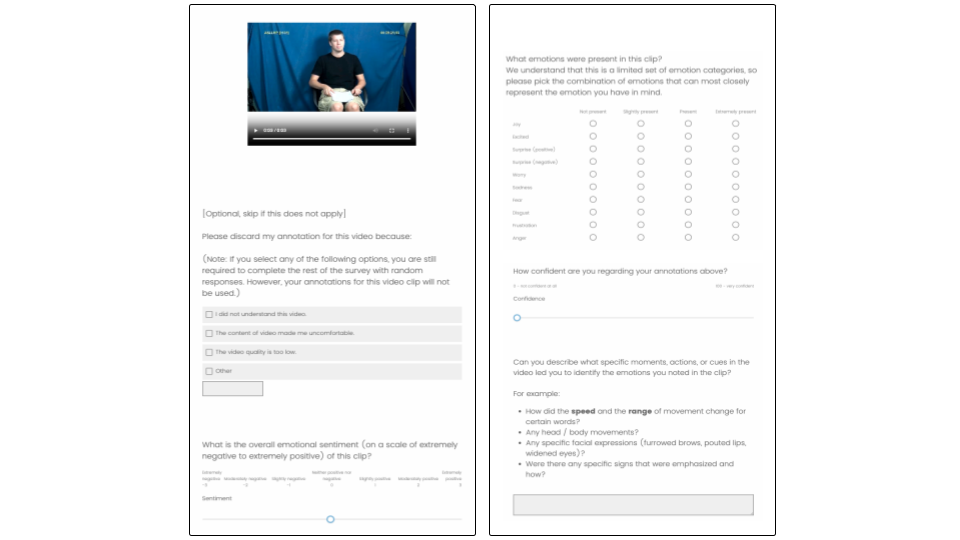
Three Deaf ASL signers with professional interpretation experience annotated each video through a structured process:
Our emotion framework builds on Ekman's basic emotions and the circumplex model of affect, expanded to capture the rich emotional expressions found in sign language. The categories were informed by prior emotion recognition datasets and pilot testing with ASL signers.
Inter-annotator agreement was measured using Krippendorff's alpha, with an average score of 0.593 across all labels. Positive emotions showed higher agreement than negative emotions, with sentiment analysis achieving α=0.738.
EmoSign is the first dedicated dataset for studying emotional expression in American Sign Language, filling a critical gap in multimodal emotion recognition research.
All emotion labels provided by Deaf ASL signers with professional interpretation experience, ensuring cultural and linguistic authenticity.
Detailed descriptions of how emotions manifest in ASL through manual and non-manual components, providing insights for future research.
Comprehensive evaluation of state-of-the-art multimodal models, revealing significant limitations in sign language emotion understanding.
This work establishes a new benchmark for multimodal AI systems and provides crucial insights for developing more emotionally-aware sign language technologies, with applications in education, healthcare, and accessibility.
We evaluated several state-of-the-art multimodal large language models (MLLMs) on EmoSign to establish baseline performance for sentiment analysis and emotion classification tasks.
Models struggle with emotion recognition from visual cues alone, with most showing strong biases toward neutral or positive predictions.
Adding text captions significantly improves model performance across all tasks.
| Model | Modality | 3-class wAcc | 3-class wF1 | 7-class wAcc | 7-class wF1 |
|---|---|---|---|---|---|
| GPT-4o | Video only | 40.72% | 24.43% | 19.81% | 5.97% |
| GPT-4o | Video + Caption | 52.13% | 76.72% | 22.89% | 26.35% |
| AffectGPT | Video only | 33.33% | 0.04% | 14.29% | 0.04% |
| AffectGPT | Video + Caption | 56.18% | 64.37% | 21.02% | 16.13% |
| Qwen2.5-VL | Video only | 27.34% | 16.47% | 10.26% | 2.44% |
| Qwen2.5-VL | Video + Caption | 41.10% | 54.29% | 15.84% | 14.51% |
| MiniGPT4 | Video only | 34.68% | 40.00% | 14.46% | 13.03% |
| MiniGPT4 | Video + Caption | 21.65% | 36.89% | 9.76% | 12.18% |
| Hearing Person | Video only | 55.64% | 57.64% | 25.48% | 21.39% |
| Model | Modality | Weighted Accuracy | Weighted F1 |
|---|---|---|---|
| GPT-4o | Video only | 11.50% | 20.76% |
| GPT-4o | Video + Caption | 35.97% | 55.09% |
| AffectGPT | Video only | 12.62% | 11.03% |
| AffectGPT | Video + Caption | 30.17% | 47.77% |
| Qwen2.5-VL | Video only | 14.39% | 18.53% |
| Qwen2.5-VL | Video + Caption | 34.96% | 44.67% |
| MiniGPT4 | Video only | 13.01% | 22.02% |
| MiniGPT4 | Video + Caption | 23.56% | 35.89% |
Key Observation: All models show significant performance improvement when provided with text captions alongside video input, highlighting the current limitations of pure visual emotion recognition in sign language.
Our analysis of annotator descriptions revealed three key types of emotion cues in ASL:
Human Baseline: A hearing, non-ASL fluent annotator achieved 55.6% accuracy on 3-class sentiment, highlighting the challenge of cross-modal emotion understanding.
@article{chua2025emosign,
title={EmoSign: A Multimodal Dataset for Understanding Emotions in American Sign Language},
author={Chua, Phoebe and Fang, Cathy Mengying and Ohkawa, Takehiko and Kushalnagar, Raja and Nanayakkara, Suranga and Maes, Pattie},
journal={39th Conference on Neural Information Processing Systems (NeurIPS 2025) Track on Datasets and Benchmarks},
year={2025},
note={Available at \url{https://huggingface.co/datasets/catfang/emosign}}
}